中共中央 国务院印发《数字中国建设整体布局规划》
《中共中央办公厅 国务院办公厅关于加快公共数据资源开发利用的意见》
Robin's Blog

关于印发《中央和国家机关工作人员赴地方差旅住宿费标准明细表》的通知(财行[2016]71号) 明细表(xls) 明细表(PDF)
根据《财政部关于明确中央和国家机关工作人员赴雄安新区差旅住宿费标准的通知》(财行〔2024〕435号)有关规定,机关工作人员赴雄安新区(不含雄县、安新县、容城县)出差的住宿费限额标准为省部级900元/人·天,厅局级550元/人·天,其他人员450元/人·天。
各地无序部署DeepSeek实无必要,该项工作需系统性开展。当前检察机关正处于信息化工作远未结束,数字化工作基础展开伊始,智能化浪潮迎面扑来的关键时刻,更需我们冷静下来,科学认识大语言模型的能力和检察机关的真实需求。当前,依托大语言模型能力对既有案件进行要素化,形成数据资源以供各级院创新业务场景使用是当务之急。最为优先的业务场景,就是案卡智能填录,或者从某种意义上说:消灭案卡。
在最高检、省院都还在摸索的时候,个别区县院就完成了“消费级显卡驱动AI检察”的魔幻场景。区县院几张消费级显卡用作体验应该还是可以,但用作业务支持就有点开玩笑了。从来都是“最高检省院主建、市县院主战”,无论是什么系统,市县院最重要职责就是提好一线需求,用好建成系统。如果是利旧来尝鲜DeepSeek还好,新购服务器来追逐热点就有点交智商税了。
当DeepSeek问答不能满足业务需求的时候,有些区县院的同学听说DeepSeek+本地知识库很香,然后就开始搞本地知识库,或者说的更专业一点,“构建本院专业法律知识库,启动检索增强生成(RAG)系统项目”——话说,这也不是基层检察院能够承担的项目啊!不客气的说,就算3000名小学生凑在一起,也写不出可媲美全国检察业务专家的公诉案件审查报告啊!
比如通过对话式交互来解决智能提取问题。有个公众号说(在没有技术积累背景下)通过部署DeepSeek梳理了电子卷宗,一键提取了关键证据……话说,这是怎样将电子卷宗“喂”给DeepSeek的?又是怎样和检察业务应用系统接口的?这是技术突破还是皇帝的新衣?至于你们信不信,我反正不信。 又比如审判监督。有个公众号说实现了智能辅助审判监督,结果在一个不太显眼的截图里面DeepSeek是这样回答的:“我只关注判决结果,不考虑案件事实、证据或量刑情节……综上所述,判决结果符合法律规定,没有问题。” (不考虑案件事实?沉默三秒……) 说好了,咱不内卷了,不要把想要实现的当成已经实现的,不要把小范围的探索当成经验宣传。这样憋着劲搞“公众号”AI攻坚战,把大家的胃口掉的高高的,这让投入几千万资金、几百位检察官实在干活的院情何以堪?本来搞出来的是很酷炫的东西,在这“绚烂”的图景下也黯然失色。
五年之前,CU检《关于案卡和系统,可以开一场三天三夜的吐槽大会》一文,检察官就提出灵魂之问:“如果填报的信息从来都生成不了有用的数据,我们一次次填报的意义到底又在哪里?”如果不是有长期项目积累基础,绝大部分院部署好的DeepSeek只能通过对话框提供服务,这种方式作为知识提供是可以的,但要具体到案件却力有不逮——你如何让DeepSeek识别你的电子卷宗?在DeepSeek和生产系统没有接口的情况下,2.0系统依然有很多流程、很多的案卡、很多的文书……如果大语言模型无法直接为检察业务系统赋能,对话式交互生成再完美的Markdown文本也只是数字花瓶。
现在AI检察炒的如火如荼,仿佛之前的工作已经成了“牛夫人”。但还是要请大家冷静冷静,当前检察机关正处于这么一个时刻:信息化工作远未结束,数字化工作基础展开伊始,今年就直面智能化的浪潮!可以说今年的任务比往年都重,这三个方向都必须齐头并进,如果只提AI,那就是“猴子掰苞谷”,而我们获得的,也只会是浮沙之上的高塔。
OCR:光学字符识别能力,将图片转为文字,提供基础感知能力。
NLU:自然语言理解能力,理解内容,对电子卷宗、法律文书进行快速解析和关键信息提取,提供业务感知能力。
NLG:自然语言生成能力,生成内容,在理解的基础上生成我们需要文书,提供业务支持能力。
AI书记员:以案件要素提取为基础的案卡填录、文书校对等基础功能全覆盖,实现案件的全要素化。
AI检察官助理:突破证据摘要与分析、类案检索与推送、信息检索与智能问答、量刑建议及量刑均衡等业务场景。
AI检察官:探索全量大数据分析、法律文书生成、公文写作等业务场景。
实践中,OCR识别错一个字可能改变案件性质,NLU误解一个条文或将颠覆司法公正。就现有的技术能力,我们现在需要的不是AI检察官,而是AI书记员。让技术回归工具本质,让机器做机器擅长的事,让检察官做检察官该做的事,才是这场技术革命的真正要义。
知识可以共享的,但案件信息不是。DeepSeek应用方式主要包括对话式交互和API接口调用。前者适合最高检在检察大数据中心集中部署“满血版”DeppSeek,集中攻关检察系统垂直大模型,构建全国检察知识库,在工作网向全国四级检察院提供知识服务。后者适合由各省级院部署检察系统垂直大模型区域镜像,站在检察业务应用系统后端通过API提供能力支持,构建本省基础库、主题库、专题库,依托生产系统的细粒度权限对内容和服务进行精准控制,有效赋能具体个案办理。
检察机关还缺乏以数据为中心的对象资源形成与调用机制。有观点认为“最好的数据治理,将是用户感受不到治理的存在,却能时刻享受到精准数据服务所带来的无形之美”。从数字检察体系来思考,数据采集、数据治理、数据服务的具体工作都不容回避,不过由于其过于宏大,在本文不展开了。
回到五年前检察官的灵魂之问,我们是不是可以做点什么了?是的,大语言模型的能力如此惊艳,我们以前想干而干不成的事情,可以考虑了:依托大语言模型能力对既有案件进行要素化,形成数据资源以供各级院创新业务场景使用! 以案卡智能填充为例:
多即是少。即便生产系统有那么多的案卡,上级院依然需要下级院上报各种数据——因为还不够,永远不够。就算毒品案件新增了毒品类型和数量的案卡项,那危险驾驶罪的血液酒精含量呢?在专业化背景下,对案件要素采集需求只会越来越多,依赖新增案卡全面描述案件是不可持续的。
少即是多。依赖大语言模型的能力,我们完全可以以电子卷宗和文书卷宗为基础全面解析案件要素,探索建立包括案件基础信息、主体信息、行为要素、证据信息、法律适用、程序事项、量刑要素、社会影响、质量评价等内容在内的案件全要素标签体系,用于结构化解析和标注案件信息,从而通过提供多维度的分析视角,构建立体化的案件管理体系。
是的,将来不需要人工填录案卡,但检察官和各级管理者却可以利用更多的案卡,真正让检察官从数据采集者角色华丽变身为数据使用者角色,真正有获得感。也许有一天,电子卷宗(最好同步建设数字卷宗体系)上传即生成全案要素,基础案卡项和动态案卡项均详细罗列在检察官的个案界面上,从此,人工填录案卡成为历史! ——不过首先,我们得聊聊哪个院负责哪个罪名的全案要素和动态案卡项,平均一个地级市负责一至两个罪名吧~
根据检务科技新动态调研,案卡填录和类案推送在限定的多个需求中高居榜首(83.1%),这也是重温五年前有关案卡填录旧文的原动力。
对案件的要素解析,DeepSeek也不一定是最佳的模型,需要评估各个大语言模型的能力选择最为适合的,标题也只是蹭个热点。
案例若有得罪之处,还请多多谅解,都是为了这项工作行稳致远。
点击原文可查阅五年前关于案卡的讨论。
,已失效。
DeepSeek成立于2023年7月17日,由知名量化资管巨头幻方量化创立。DeepSeek 是一家创新型科技公司,长久以来专注于开发先进的大语言模型(LLM)和相关技术,作为大厂外唯一一家储备万张 A100 芯片的公司,幻方量化为DeepSeek的技术研发提供了强大的硬件支持。当其他互联网大厂抢购H100芯片时,DeepSeek尝试做了件事:把自家模型移植到华为昇腾910B芯片运行。通过“动态精度调节”技术,他们在同等任务下性能损失仅5%,但成本下降70%。2025年1月20日,DeepSeek正式发布 DeepSeek-R1 模型,并同步开源模型权重。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。DeepSeek-V3和DeepSeek-R1两款大模型,成本价格低廉,性能与OpenAI相当,让硅谷震惊。
帮我写作一篇关于DeepSeek与ChatGPT对比的文章,第一部分是ChatGPT的研发历程与性能描述,第二部分是DeepSeek的研发历程与性能描述,第三部分是DeepSeek的优势,第四部分是DeepSeek的发展方向。
DeepSeek与ChatGPT对比分析
第一部分:ChatGPT的研发历程与性能描述
研发历程
ChatGPT是由OpenAI开发的一款基于生成式预训练变换器(GPT)架构的大型语言模型。其研发历程可以追溯到2018年,当时OpenAI发布了GPT-1,这是第一个基于Transformer架构的预训练语言模型。随后,OpenAI在2019年推出了GPT-2,该模型在生成文本方面表现出色,但由于其潜在的滥用风险,OpenAI最初并未完全公开模型。2020年,OpenAI发布了GPT-3,这是一个拥有1750亿参数的巨大模型,其在自然语言处理任务中表现出前所未有的能力。ChatGPT是基于GPT-3.5和GPT-4的改进版本,专门针对对话任务进行了优化,能够生成更加连贯和上下文相关的回复。
性能描述
ChatGPT在多个自然语言处理任务中表现出色,尤其是在对话生成、文本摘要、翻译和问答系统等方面。其强大的上下文理解能力和生成能力使得它在与用户的交互中显得非常自然和流畅。ChatGPT能够处理复杂的对话场景,理解多轮对话中的上下文,并生成符合语境的回复。此外,ChatGPT还具备一定的推理能力,能够进行简单的逻辑推理和问题解决。
第二部分:DeepSeek的研发历程与性能描述
研发历程
DeepSeek是由深度求索(DeepSeek)公司开发的一款专注于搜索和知识问答的人工智能系统。其研发历程始于对现有搜索引擎和问答系统的不足进行深入分析,旨在提供更加精准和高效的搜索体验。DeepSeek的研发团队在自然语言处理、信息检索和机器学习领域积累了丰富的经验,经过多年的技术积累和迭代,最终推出了DeepSeek系统。DeepSeek的核心技术包括深度学习、知识图谱和语义理解等,这些技术的结合使得DeepSeek在搜索和问答任务中表现出色。
性能描述
DeepSeek在搜索和知识问答任务中表现出色,尤其是在处理复杂查询和提供精准答案方面。其强大的语义理解能力使得它能够准确理解用户的查询意图,并从海量数据中快速找到相关信息。DeepSeek还具备强大的知识图谱,能够将不同领域的知识进行关联,提供更加全面和深入的答案。此外,DeepSeek在实时搜索和动态更新方面也表现出色,能够及时捕捉最新的信息并反馈给用户。
第三部分:DeepSeek的优势
精准搜索
DeepSeek在搜索任务中的精准度是其最大的优势之一。通过深度学习技术和知识图谱的结合,DeepSeek能够准确理解用户的查询意图,并从海量数据中快速找到相关信息。相比传统的搜索引擎,DeepSeek能够提供更加精准和个性化的搜索结果。
知识问答
DeepSeek在知识问答任务中的表现也非常出色。其强大的语义理解能力和知识图谱使得它能够处理复杂的查询,并提供全面和深入的答案。相比ChatGPT,DeepSeek在提供事实性答案和专业知识方面更具优势。
实时更新
DeepSeek具备实时搜索和动态更新的能力,能够及时捕捉最新的信息并反馈给用户。这使得DeepSeek在新闻搜索、实时事件跟踪等任务中表现出色。
第四部分:DeepSeek的发展方向
多语言支持
未来,DeepSeek将进一步扩展其多语言支持能力,覆盖更多的语言和地区。通过多语言模型的训练和优化,DeepSeek将能够为全球用户提供更加精准和高效的搜索和问答服务。
垂直领域深耕
DeepSeek计划在垂直领域进行深耕,特别是在医疗、法律、金融等专业领域。通过构建领域-specific的知识图谱和模型,DeepSeek将能够提供更加专业和精准的搜索和问答服务。
用户体验优化
DeepSeek将继续优化用户体验,特别是在搜索结果的可视化和交互方面。通过引入更加直观和友好的用户界面,DeepSeek将能够提升用户的搜索体验,并提高用户满意度。
人工智能融合
DeepSeek计划进一步融合人工智能技术,特别是在自然语言处理和机器学习领域。通过引入更加先进的模型和算法,DeepSeek将能够提升其搜索和问答的性能,并拓展其应用场景。
通过以上发展方向,DeepSeek将继续保持在搜索和知识问答领域的领先地位,并为用户提供更加精准、高效和智能的服务。
李勇:《DeepSeek那份讯问提纲有惊喜也有不专业和误导》
学习资料(PDF/PPT):
02-AIGC发展研究3.0版0.95(公众号发布) 2025-2-14
03-DeepSeek DeepResearch:让科研像聊天一样简单(100页完整版) 2025-2-21
标准号:GB/T 22239-2019
中文标准名称:信息安全技术 网络安全等级保护基本要求
等保1.0-GBT22239-2008《信息安全技术信息系统安全等级保护基本要求》
等保2.0-GBT22239-2019《信息安全技术网络安全等级保护基本要求》
“动画+长图”,带您收阅成都检察答卷
https://mp.weixin.qq.com/s/NBtAWaw4iiDIi1XECpB7SA
《成都市人民检察院工作报告》解读
https://mp.weixin.qq.com/s/l9eGRcBqFuGuTFhw8RD0_Q
两会时间丨听取人大代表、政协委员意见建议
https://mp.weixin.qq.com/s/9AIgitOtwAW-LEPl2uqhQQ
99.2%!成都市人民检察院工作报告获高票通过
https://mp.weixin.qq.com/s/rkt5fWNC3pFDQ2G1dGNPhQ
成都召开智慧蓉城建设工作推进会,要求全面提升建设质效,更好惠企惠民惠基层,为超大城市转型发展提供科学治理支撑
今年以来,全市各级各部门按照“1+4+2”总体部署,全面推进城市运行“一网统管”、政务服务“一网通办”、数据资源“一网通享”、社会诉求“一键回应”,智慧蓉城“王”字型城市管理架构初步构建,数据治理有序开展,应用场景建设加快推进,社会诉求响应更加及时有效,各方面工作取得阶段性成效。但要清醒认识到,数据采集和挖掘、应用场景打造、市民企业体验、数字经济培育发展等方面仍存在短板不足。
——要聚焦重点、攻坚突破,推动智慧蓉城建设提质增效。
◆要以数据质量提升工作质量。
完善全市数据资源标准体系、考核指标和工作体系。推进三级首席数据官、数据执行官、数据专员实战化运行。
强化数据分析、提升业务质效。政务服务要让“数据多跑路、群众少跑腿”,行业监管要让“数据多发力、协同更高效”,经济运行要让“数据多说话、决策更科学”。
建立数据共享机制,破除信息壁垒和“孤岛”。
以“建圈强链”理念推动数据资源要素化、资产化开发,赋能经济发展。
构建数据库“防火墙”,实现数据“可用不可见”,牢牢守住数据安全底线。
◆要以数字基础设施支撑城市智慧运行。
筑牢数字资源底座支撑,持续完善市级基础数据库和重点领域主题库,建立统一人口数据资源体系。
加快推进城市“感知一张网”建设。
建强先进算力和区块链基础设施。
◆要以智慧应用场景提升服务管理水平。
在建设方式上要统分结合。
在建设内容上要惠企便民。
在应用推广上要优胜劣汰。
——要科学作为、精准发力,高质高效推进智慧蓉城建设。
◆要突出技术与机制双轮驱动,智慧蓉城建设领导小组要发挥牵头抓总作用,市领导要常态化分析把握城市生命体征,推动分管部门场景应用创新,市城运中心、市网络理政办要组织、指导、赋能各业务主管部门和基层开展工作,市级部门要提供业务场景拆分应用和行业数据回流赋能,各区(市)县要构建形成区域的城市运行生命体征指标体系,主要领导要讲得清、亲自抓、真应用,不断优化辖区高效管理和有效服务,坚决防止造成技术“垃圾桶”和信息化“烂尾楼”。
◆要突出线上与线下深度融合,持续推进智慧蓉城与“微网实格”融合运行,完善“立体感知—及时预警—快速处置”工作闭环。
◆要突出政府与社会协同发力,拓宽渠道吸引市场主体和公众参与,强化专家智库智力支撑,推动“数据下基层”,为基层干部减负提能。
◆要突出激励与约束并重,树牢正确政绩观,加大考核评价力度。
2023年11月14日,成都市人民检察院召开“数字检察赋能法律监督”新闻发布会,发布2023年以来成都市检察机关开展数字检察工作情况。党组副书记、副检察长苏云,党组成员、副检察长胡立新及相关部门负责人参加发布会。

新华社:《四川:大数据检察监督模型让“水耗子”无处遁形》(https://h.xinhuaxmt.com/vh512/share/11766792)
农民日报:《大数据模型“揭发”屠宰企业违法盗用地下水》
(https://szb.farmer.com.cn/2023/20231220/20231220_005/20231220_005_4.htm)
最高检:《【新华社】四川:大数据检察监督模型让“水耗子”无处遁形》(https://mp.weixin.qq.com/s/hJ3dAwYjBc1lm5lR9mVO9g)
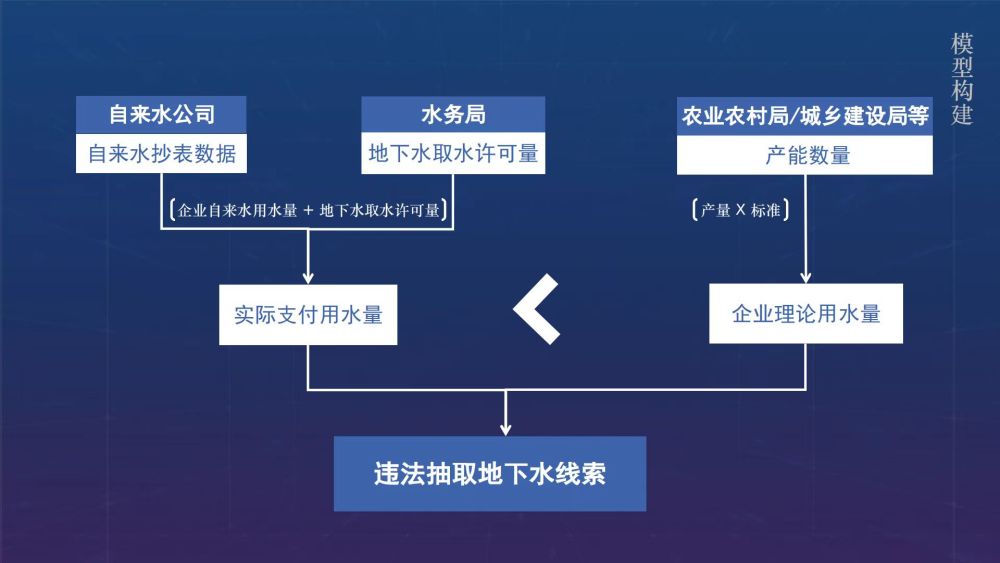
四川法治报 :《大数据里的隐藏线索 成都检察举行“数字检察赋能法律监督”新闻发布会》(https://fzscapp.scfzbs.com//appDetail?article_id=221883)
成都日报:《数字检察赋能法律监督 看“个案”如何撬动“治理”》(https://v5share.cdrb.com.cn/h5/detail/normal/5540917669987328)
新浪:《成都市人民检察院举行“数字检察赋能法律监督”新闻发布会》(https://sc.sina.cn/city/2023-11-14/detail-imzuqitt3626270.d.html)
腾讯网:《成都市人民检察院举行“数字检察赋能 法律监督”新闻发布会》(https://new.qq.com/rain/a/20231114A04HAG00)
一点资讯:《成都市人民检察院举行“数字检察赋能 法律监督”新闻发布会》(https://www.yidianzixun.com/article/0s5QPsPa)
封面新闻:《今年来成都检察构建应用类监督模型11个 用数字赋能法律监督》(https://m.thecover.cn/news_details.html?eid=K%2BkY/Q6oATuH90qSdq8Jkw)
成都检察:《成都市人民检察院举行“数字检察赋能法律监督”新闻发布会》(https://mp.weixin.qq.com/s/nbmd_LQMQhHv5_uhEEQ-OA)
以前一直不太在博客里面添加图片,因为图片会大量的占用虚拟主机空间,迁移时也很麻烦。外链的图片,往往容易失效,更多的是“地方保护主义”,不让“盗链”。
直到最近,有了OSS,就可以自己弄“图床”——忽然发现,20年前的很多很简单的东西,却用最时髦的词汇来描述,有点意思^_^
